Podczas Tesla AI Day 2021 firma zaprezentowała procesor Dojo D1, który ma zasilać superkomputer Dojo. Opowieść była mocno technologiczna, rozpaliła pewnie przede wszystkim miłośników superkomputerów, ale płynie z niej pewien jasny komunikat: na rynku specjalistycznych procesorów pojawił się nowy gracz.
Procesor Dojo D1 i superkomputer Dojo w liczbach
Spis treści
Procesor Dojo D1 to specjalizowany układ wykonany w technologii 7 nm, który powstał w wyniku potrzeby „wyrażonej przez Elona Muska”. Układ składa się z 50 miliardów tranzystorów, co najmniej 18 kilometrów połączeń i ma 400 watów TDP (może oddać maksymalnie tyle ciepła). Moc obliczeniowa Dojo D1 to 362 teraFLOPS-y przy kalkulacjach istotnych z punktu widzenia szkolenia sztucznej oraz 22,6 teraFLOPS-a przy klasycznych obliczeniach zmiennoprzecinkowych z 32-bitową precyzją.
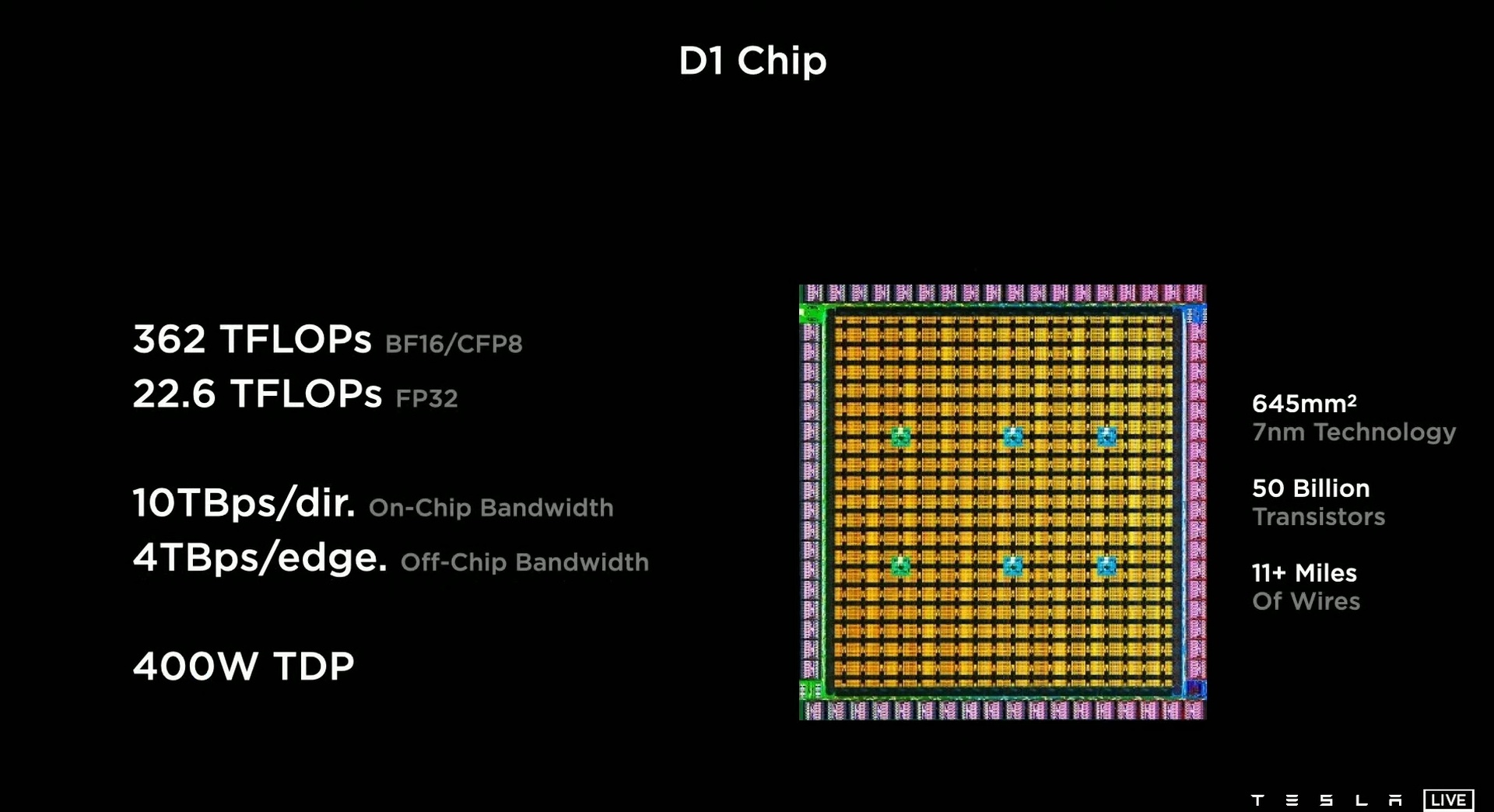

Czy to dużo? Bardzo! Dla porównania: nawet przy najszybszych współcześnie stosowanych procesorach ogólnego zastosowania (np. Intel Core i5, AMD Ryzen itd.) stosuje się przedrostek giga-, a więc skalę 1000x niższą. Osiągają one kilkadziesiąt do maksymalnie kilkuset gigaFLOPS-ów. Znacznie lepiej wypadają procesory specjalistyczne, szczególnie układy graficzne.
Gdzie jest konkurencja?
Zastosowany w Tesli Model S Plaid układ APU (Ryzen + Radeon) kompatybilny z architekturą RDNA 2 ma mieć szczytową wydajność wynoszącą do 10 teraFLOPS-ów. Dojo D1 będzie więc dwukrotnie bardziej wydajny niż jeden z najszybszych GPU na świecie. Będzie na poziomie lub minimalnie wydajniejszy niż układy Nvidii wykorzystujące architekturę Pascal, które osiągały „ponad 21 teraFLOPS-ów” [dane producenta], a przegra jedynie z układami Nvidia Volta, które obiecują 125 teraFLOPS-ów dzięki 640 jednostkom tensorowym.

Układ Nvidia Volta (c) Nvidia
Ale ta „przegrana” nie jest wcale taka oczywista, jeśli wziąć pod uwagę to, na co zwrócił uwagę główny inżynier Tesli: moc obliczeniową pojedynczego procesora skaluje się znacznie łatwiej niż moc połączonych układów. Ta ostatnia zależy bowiem od przepustowości magistrali spinającej układy oraz łączącej je z pamięcią.
I tutaj różnice są kolosalne: Tesla chwali się, że procesory Dojo D1 są w stanie osiągnąć do 4 TB/s (4 000 GB/s), podczas gdy NVLink 3.0 Nvidii osiąga 600 GB/s, a NVLink 4.0 stosowany w architekturze Volta ma oferować „2x wyższą przepustowość”, co daje 1 200 GB/s (źródło).
Dojo D1 jak Nvidia Pascal, ale z o niebo szybszą magistralą
To nie koniec: Tesla nie chce bawić się w ręczne obsadzanie procesorów na płytach, lecz stworzyła kompletny zestaw 25 procesorów Dojo D1 w postaci samodzielnego modułu (ang. tile, pol. płyta, kafel). Teoretyczna maksymalna moc obliczeniowa takiego układu to 565 teraFLOPS-ów (FP32), a więc 4,5 raza więcej niż obiecuje Nvidia w układach Volta.
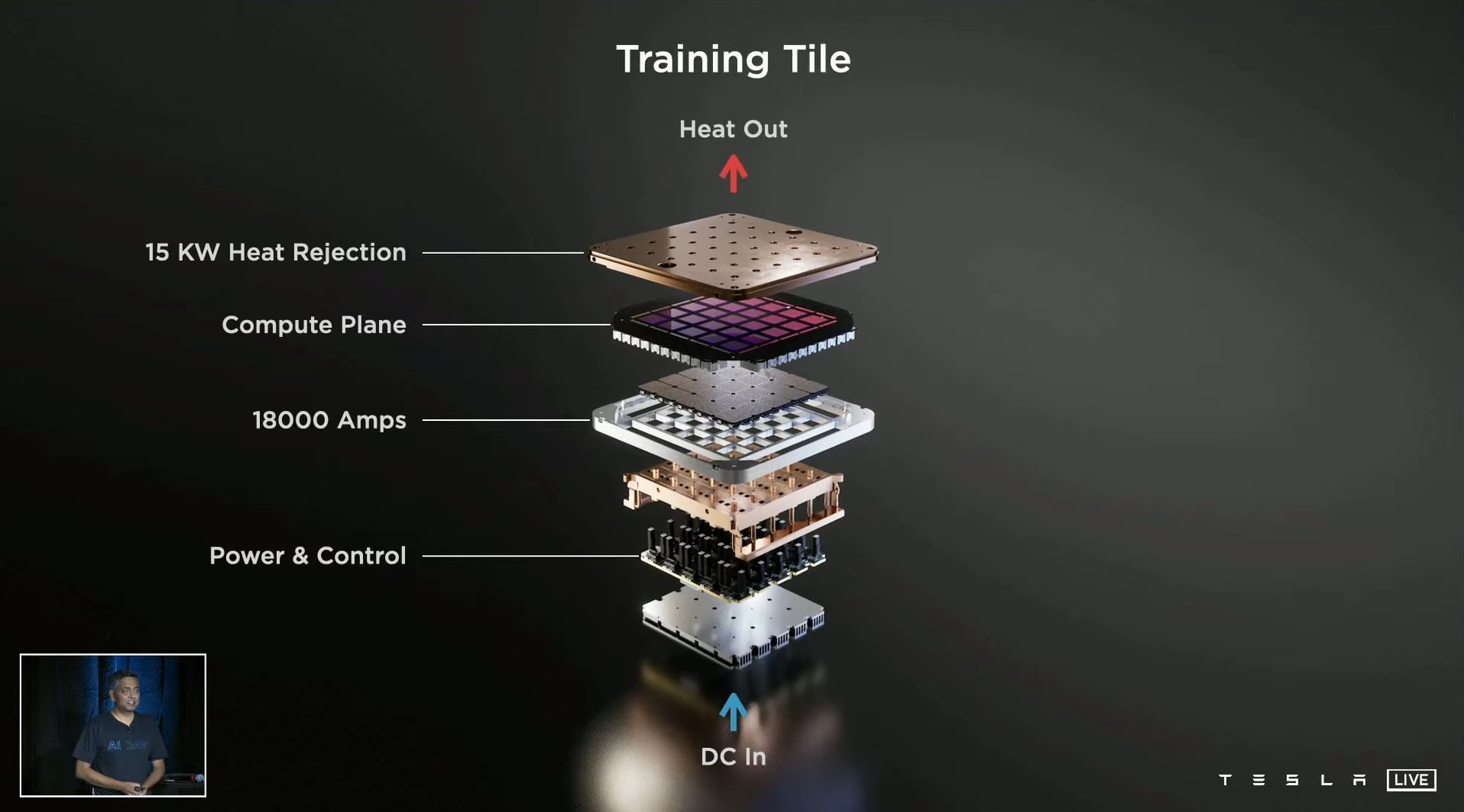

Tyle że do trenowania sztucznej inteligencji nie są potrzebne – przynajmniej: nie zawsze są potrzebne – obliczenia na 32-bitowych rejestrach (FP32). Stąd też Tesla podaje wydajność przy 16- i 8 bitach. A tutaj taka płytka treningowa (AI training tile) ma oferować 9 petaFLOPS-ów wydajności i przepustowość wynoszącą 36 TB/s. Jedna płytka o objętości grubawego laptopa!
6 zestawów z płytami treningowymi poproszę
Opowieść nie kończy się jednak w tym miejscu. Tesla chce montować po trzy takie moduły w jednej kieszeni (na jednej tacy, płycie) i takie trójki łączyć w pary w szafkach (3×2):

Dwadzieścia takich szafek zostanie zestawionych w jeden węzeł o nazwie ExaPOD. Dzięki 3 000 układów Dojo D1 jego maksymalna moc obliczeniowa ma wynieść 1,1 eksaFLOPS-a przy operacjach 8- i 16-bitowych. Dla porównania: japoński Fugaku, najszybszy superkomputer na świecie, osiągnął w AI poziom 1,42 eksaFLOPS-a zaledwie rok temu (FP16), w czerwcu 2020 roku. Był on pierwszą maszyną na świecie, która przekroczyła poziom 1 eksa- – dziś ma już wydajność 2 eksaFLOPS-ów.

Wizualizacja ExaPOD-a, superkomputera Dojo. Zwróć uwagę na brzegi ilustracji, wygląda na to, że patrzymy na cały układ, jedną stojącą pod ścianą szafę. Porównaj tę wizualizację ze zdjęciem poniżej (c) Tesla
I to właśnie ten ExaPOD ma być superkomputerem Dojo. Tesla nie pokazała, jak wyglądają opisywane szafki, ale z wizualizacji wynika, że dwie takie szafki leżące obok siebie będą mniej więcej wielkości szuflady, jaka bywa stosowana w niektórych łóżkach. Czyli dwadzieścia szafek powinno mieć rozmiary zwykłej dużej szafy na ubrania, choć w tym ostatnim przypadku należy zastrzec, że systemy chłodzenia (cieczą) mogą dodać drugie tyle objętości.
Nawet jeśli ExaPOD / Dojo będzie odpowiednikiem sześciu stojących obok siebie szaf serwerowych (tj. dwóch-trzech dużych szaf na ubrania), mamy do czynienia z wyjątkowo kompaktowym układem. Współczesne superkomputery zajmują sporej wielkości wentylowane pomieszczenia i składają się z dziesiątek lub setek szaf. Oto fragment hali, na której zestawiono superkomputer Sierra:

Liczbę węzłów, eksa-modułów prawdopodobnie będzie można zwiększać tworząc gigantyczne AI-superkomputery. ExaPOD-a / Dojo jeszcze nie ma, ma on być gotowy dopiero w 2022 roku. Jeśli Tesla dotrzyma obietnicy dotyczącej wydajności układu, Nvidia będzie mogła zacząć się bać. Tesla już podgryzła ją w segmencie układów do przetwarzania AI w zastosowaniach mobilnych (procesory NNA w komputerze FSD), a teraz uderza w drugi wysokomarżowy segment: stacjonarne procesory wspomagające AI.
Nota od redakcji www.elektrowoz.pl: ani inżynierowie Tesli, ani jej prezes nawet o tym nie napomknęli, ale wygląda na to, że procesory Dojo D1 mogłyby się dziś okazać najszybszymi GPU na świecie. W grach ultrawysoka precyzja obliczeń nie jest potrzebna – nie ma znaczenia, czy postać będzie miała jedną linię tutaj czy o 0,0001 milimetra dalej – liczy się natomiast szybkość wypluwania z siebie liczb. A Dojo D1 zaprojektowano właśnie do tego.













